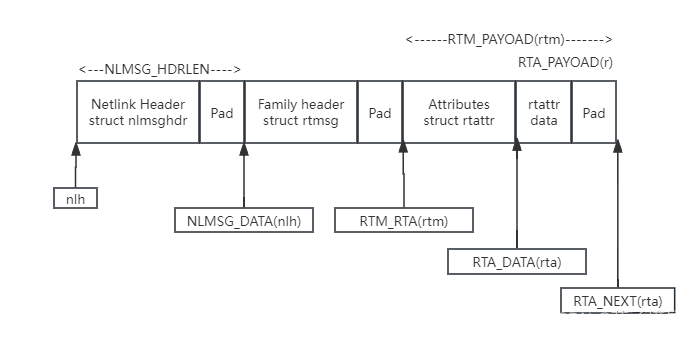
最大匹配算法是一种常见的中文分词算法,其核心思想是从左向右取词,以词典中最长的词为优先匹配。这里我将为你展示一个简单的最大匹配分词算法的实现,并结合输入任意句子、显示分词结果以及计算分词召回率。
代码 :
# happy coding
# -*- coding: UTF-8 -*-
'''
@project:NLP
@auth:y1441206
@file:最大匹配法分词.py
@date:2024-06-30 16:08
'''
class MaxMatchSegmenter:
def __init__(self, dictionary):
self.dictionary = dictionary
self.max_length = max(len(word) for word in dictionary)
def segment(self, text):
result = []
index = 0
n = len(text)
while index < n:
matched = False
for length in range(self.max_length, 0, -1):
if index + length <= n:
word = text[index:index+length]
if word in self.dictionary:
result.append(word)
index += length
matched = True
break
if not matched:
result.append(text[index])
index += 1
return result
def calculate_recall(reference, segmented):
total_words = len(reference)
correctly_segmented = sum(1 for word in segmented if word in reference)
recall = correctly_segmented / total_words if total_words > 0 else 0
return recall
# Example usage
if __name__ == "__main__":
# Example dictionary
dictionary = {"北京", "天安门", "广场", "国家", "博物馆", "人民", "大会堂", "长城"}
# Example text to segment
text = "北京天安门广场是中国的象征,国家博物馆和人民大会堂也在附近。"
# Initialize segmenter with dictionary
segmenter = MaxMatchSegmenter(dictionary)
# Segment the text
segmented_text = segmenter.segment(text)
# Print segmented result
print("分词结果:", " / ".join(segmented_text))
# Example for calculating recall
reference_segmentation = ["北京", "天安门广场", "是", "中国", "的", "象征", ",", "国家", "博物馆", "和", "人民大会堂", "也", "在", "附近", "。"]
recall = calculate_recall(reference_segmentation, segmented_text)
print("分词召回率:", recall)运行结果 :